










Getty Images
Bing, Microsoft’s search engine platform, went down in the very early morning today. That meant that searches from Microsoft’s Edge browsers that had yet to change their default providers didn’t work. It also meant that services relying on Bing’s search API—Microsoft’s own Copilot, ChatGPT search, Yahoo, Ecosia, and DuckDuckGo—similarly failed.
Services were largely restored by the morning Eastern work hours, but the timing feels apt, concerning, or some combination of the two. Google, the consistently dominating search platform, just last week announced and debuted AI Overviews as a default addition to all searches. If you don’t want an AI response but still want to use Google, you can hunt down the new “Web” option in a menu, or you can, per Ernie Smith, tack “&udm=14” onto your search or use Smith’s own “Konami code” shortcut page.
If dismay about AI’s hallucinations, power draw, or pizza recipes concern you—along with perhaps broader Google issues involving privacy, tracking, news, SEO, or monopoly power—most of your other major options were brought down by a single API outage this morning. Moving past that kind of single point of vulnerability will take some work, both by the industry and by you, the person wondering if there’s a real alternative.
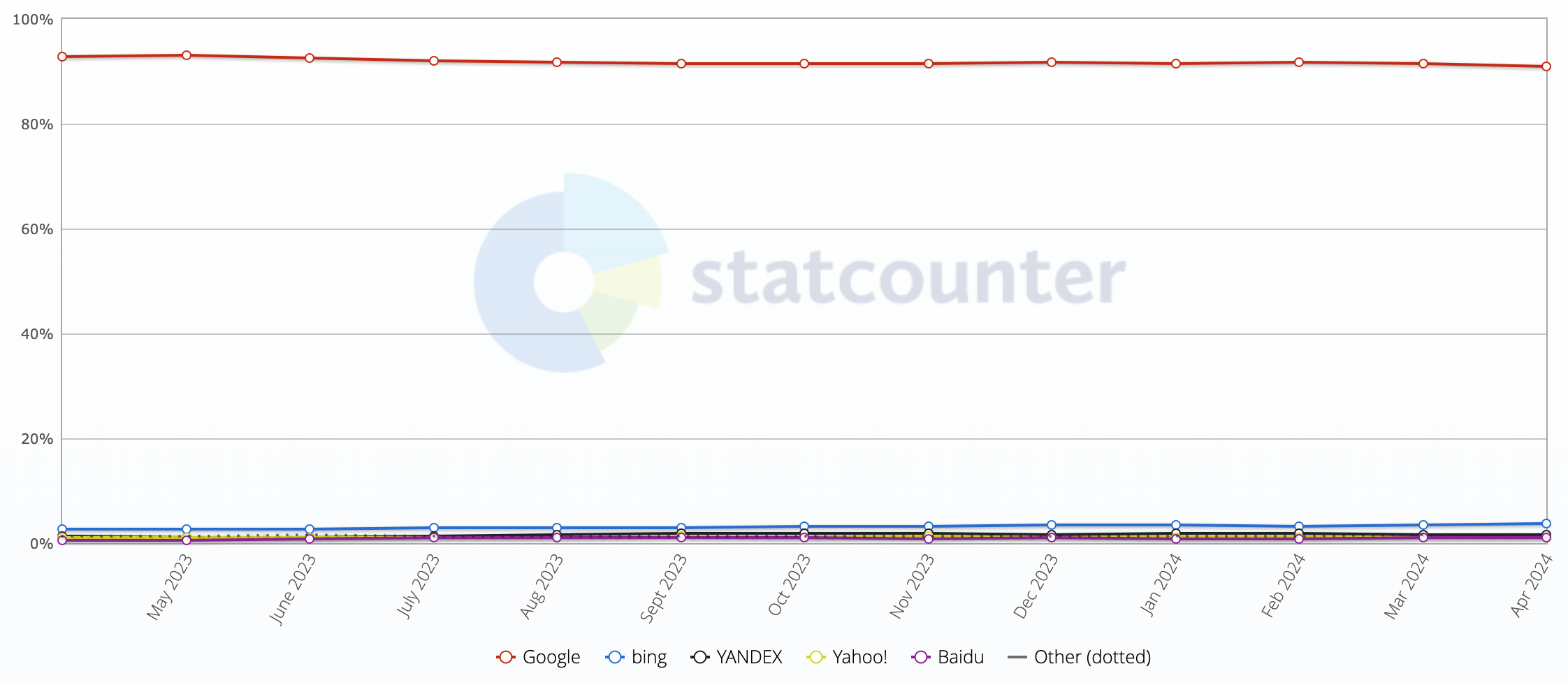
Search engine market share, as measured by StatCounter, April 2023–April 2024.
StatCounter
Upwards of a billion dollars a year
The overwhelming majority of search tools offering an “alternative” to Google are using Google, Bing, or Yandex, the three major search engines that maintain massive global indexes. Yandex, being based in Russia, is a non-starter for many people around the world at the moment. Bing offers its services widely, most notably to DuckDuckGo, but its ad-based revenue model and privacy particulars have caused some friction there in the past. Before his company was able to block more of Microsoft’s own tracking scripts, DuckDuckGo CEO and founder Gabriel Weinberg explained in a Reddit reply why firms like his weren’t going the full DIY route:
… [W]e source most of our traditional links and images privately from Bing … Really only two companies (Google and Microsoft) have a high-quality global web link index (because I believe it costs upwards of a billion dollars a year to do), and so literally every other global search engine needs to bootstrap with one or both of them to provide a mainstream search product. The same is true for maps btw — only the biggest companies can similarly afford to put satellites up and send ground cars to take streetview pictures of every neighborhood.
Bing makes Microsoft money, if not quite profit yet. It’s in Microsoft’s interest to keep its search index stocked and API open, even if its focus is almost entirely on its own AI chatbot version of Bing. Yet if Microsoft decided to pull API access, or it became unreliable, Google’s default position gets even stronger. What would non-conformists have to choose from then?
What it looks like beyond Google and Bing
It would be much harder to know what exists beyond “GBY” (Google, Bing, Yandex) and how it all works without the work of
What stands out? Mojeek (“it’s not bad… I’d live”) and Stract (“a useful supplement to more major engines”) are two of Kumar’s favorites. Right Dao has “very fast, good results,” in part because its crawler starts off from Wikipedia. Yep reaches farther out, showing results that link to and back from sites related to your query and also promises to share ad revenue with creators. All of them show promise, but you get the sense that they’re a second car, or a third bicycle, rather than a primary transport.
There are far smaller-scoped engines in other sections of Kumar’s post. If you’re wondering where that one other search engine you’ve heard about is, it’s probably in the “Semi-independent indexes” section, because it uses a GBY index when its own results are not strong enough. Here you’ll find cryptocurrency-friendly, controversy-courting-founder-having Brave, a few engines that either “resell” GBY results or stuff affiliate links into them, and “the most interesting entry,” according to Kumar, Kagi.
Kagi requires an account and uses its own index, Teclis, in combination with Google, Bing, Yandex, Mojeek, and others, including, notably, Brave. Kagi’s founder has strong opinions on the AI-based future of search and responding to harmful searches in ways that are not “scalable.” How much of that does or does not bother you will vary, but it’s worth noting that Kagi also suffers when the GBY triumvirate is restricted.
Something besides search?
Many non-GBY search engines rely on, or start with, the Common Crawl, a public resource of more than 250 billion web pages across 17 years, with billions of pages added every month. In some ways, all the information you need is right there; the Common Crawl is a fundamental part of training many Large Language Model AIs. In other, more accurate ways, the real work is figuring out how to organize, rank, and present those results in a way that users like and that, somehow, makes you money.
Going farther than the Crawl costs massive amounts of money and infrastructure, as the founders of DuckDuckGo and Kagi can attest. Google has advertising to sell and a browser and Android phones and many bundled services that benefit from its engine. Microsoft also has ads, but also a browser and an operating system in which to bundle Bing. How can anyone else afford to offer up search results without relying, in part, on these two (and, sometimes, Yandex)?
Trying to work out this question has helped me understand why there’s so much energy behind AI, or at least the platonic ideal of an actual search assistant guiding you beyond the typical GBY offerings. These days, if I can’t stand the results from a web search, I’ll typically head to Reddit and look for enthusiasts’ takes. But now, of course, Reddit’s posts are being fed into ChatGPT and Google and other AI concerns. The results from different GBY-sourced engines can be very different, and sometimes fascinating, but they still originate from primarily two or three sources.
I think the answer for anyone who really wants an alternative, which has perhaps always been the answer, is, simply, putting in the work. Keep a few different search engines, forums, and other resources bookmarked. Dig deeper into books, libraries, non-indexed databases, and, heaven help you, other people. The easiest answers might be locked up in the GBY networks for some time still, but not all the answers.
A web comic that will never leave my brain, but is fuzzy and which I can’t find at the moment (maybe xkcd?), is about life before Google. Somebody sitting on a couch says out loud, “I wish I knew more about metallurgy.” In the next panel, they sigh and say, “Oh well.” I try to appreciate all that search has given me, while still hoping that, at some point, it might not be left to only two of the world’s largest companies overseeing most of the backend.











+ There are no comments
Add yours